Data science can’t start their work until the data cleaning process is complete. Learn about the role of the data warehouse as a repository of analysis-ready datasets.
As a data scientist, it’s valuable to have some idea of fundamental data warehouse concepts. Most of the work we do involves adding enterprise value on top of datasets that need to be clean and readily comprehensible. For a dataset to reach that stage of its lifecycle, it has already passed through many components of data architecture and, hopefully, many data quality filters. This is how we avoid the unfortunate situation wherein the data scientist ends up spending 80% of their time on data wrangling.
Let’s take a moment to deepen our appreciation of the data architecture process by learning about various considerations relevant to setting up a data warehouse.
The data warehouse is a specific infrastructure element that provides down-the-line users, including data analysts and data scientists, access to data that has been shaped to conform to business rules and is stored in an easy-to-query format.
The data warehouse typically connects information from multiple “source-of-truth” transactional databases, which may exist within individual business units. In contrast to information stored in a transactional database, the contents of a data warehouse are reformatted for speed and ease of querying.
The data must conform to specific business rules that validate quality. Then it is stored in a denormalized structure — that means storing together pieces of information that will likely be queried together. This serves to increase performance by decreasing the complexity of queries required to get data out of the warehouse (i.e., by reducing the number of data joins).
In this guide:
- Architecting the Data Warehouse
- Enhancing Performance and Adjusting Size
- Related Data Storage Options
- Working with Big Data
- Extract, Transform, Load (ETL)
- Getting Data out of the Warehouse
- Data Archiving
- Summary
Architecting the Data Warehouse
In the process of developing the dimension model for the data warehouse, the design will typically pass through three stages: (1) business model, which generalizes the data based on business requirements, (2) logical model, which sets the column types, and (3) physical model, which represents the actual design blueprint of the relational data warehouse.
Because the data warehouse will contain information from across all aspects of the business, stakeholders must agree in advance to the grain (i.e. level of granularity) of the data that will be stored.
Reminder to validate the model across various stakeholder groups before implementation.
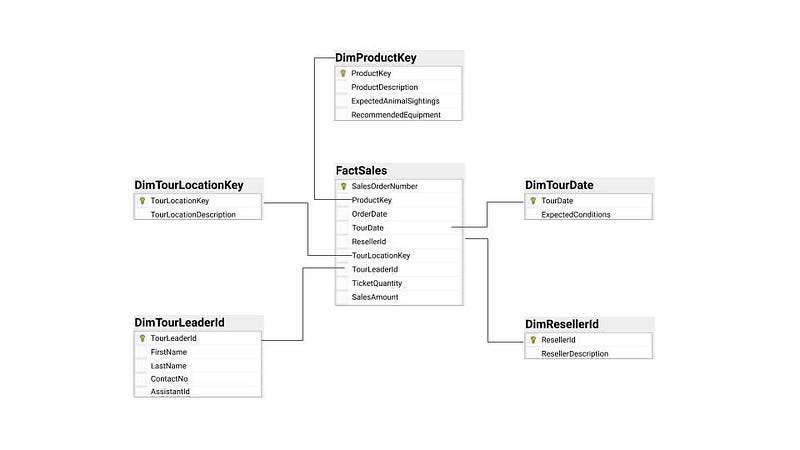
The underlying structure in the data warehouse is commonly referred to as the star schema — it classifies information as either a dimension or fact (i.e., measure). The fact table stores observations or events (i.e. sales, orders, stock balances, etc.) The dimension tables contain descriptive information about those facts (i.e. dates, locations, etc.)
There are three different types of fact tables: (1) transactional for records at the standardized grain, (2) periodic for records that fall within a given time frame, (3) cumulative for records that fall within a given business process.
In addition to the star schema, there’s also the option to arrange data into the snowflake schema. The difference here is that each dimension is normalized. Normalization is a database design technique for creating records that contain an atomic level of information. However, the snowflake schema adds unnecessary complexity to the dimension model — usually the star schema will suffice.
Enhancing Performance and Adjusting for Size
In addition to understanding how to structure the data, the person designing the data warehouse should also be familiar with how to improve performance.
One performance-enhancing technique is to create a clustered index on the data in the order it is typically queried. So for example, we might choose to organize the fact table by TourDate descending, so the tours that are coming up next will be shown first in the table. Setting up a clustered index reorders the way the records are physically stored, promoting speed of retrieval. In addition to an optional, single clustered index, a table can also have multiple non-clustered indices that won’t impact how the table is physically stored, but rather create additional copies in memory.
Another performance enhancement involves splitting up very large tables into multiple smaller parts. This is called partitioning. By splitting a large table into smaller, individual tables, queries that need access to only a fraction of the data can run faster. Partitioning can be either vertical (splitting up columns) or horizontal (splitting up rows). Here’s a link where you can download an .rtf file containing partitioning script for SQL along with other database architecture resources like a project launch and management checklist.

Taking total database size into account is another a crucial component of tuning performance. Estimating the size of the resulting database when designing a data warehouse will help align performance with application requirements according to service level agreement (SLA). Moreover, it will provide insight into the budgeted demand for physical disk space or cost of cloud storage.
To conduct this calculation, simply aggregate the size of each table, which depends largely on the indexes. If database size is significantly larger than expected, you may need to normalize aspects of the database. Conversely, if your database ends up smaller, you can get away with more denormalization, which will increase query performance.
Related Data Storage Options
The data in a data warehouse can be reorganized into smaller databases to suit the needs of the organization. For example, a business unit might create a data mart, with information specific to their department. This read-only info source provides clarity and accessibility for business users who might be a little further from the technical details of data architecture. Here’s a planning strategy to deploy when creating a data mart.
Similarly, an operational data store (ODS) can be set up for operational reporting. The Master Data Management (MDM) system stores information about unique business assets (i.e., customers, suppliers, employees, products, etc.)
Read about the risks of overutilizing data visualization tools for business intelligence.
Working with Big Data
To handle big data, a data architect might chose to implement a tool such as Apache Hadoop. Hadoop was based on the MapReduce technique developed by Google to index the world wide web and was released to the public in 2006. In contrast to the highly structured environment of the data warehouse, where information has already been validated upstream to conform to business rules, Hadoop is a software library that accepts a variety of data types and allows for distributed processing across clusters of computers. Hadoop is often used to process streaming data.
While Hadoop is able to quickly process streaming data, it struggles with query speed, complexity of queries, security, and orchestration. In recent years, Hadoop has been falling out of favor as cloud-based solutions (e.g., Amazon Kinesis) have risen to prominence — offering the same gains in terms of speed for processing unstructured data while integrating with other tools in the cloud ecosystem that address these potential weaknesses.
Read more about how to approach the implementation of “new” database technologies.
Extract, Transform, Load (ETL)
Extraction, transformation, and load define the process of moving the data out of its original location (E), doing some form of transformation (T), then loading it (L) into the data warehouse. Rather than approach the ETL pipeline in an ad hoc, piecemeal fashion, database architect should look to implement a systematic approach that takes into account best practices around design considerations, operational issues, failure points, and recovery methods. See also this helpful resource for setting up an ETL pipeline.
Documentation for ETL includes creating source-to-target mapping: the set of transformation instructions on how to convert the structure and content of data in the source system to the structure and content of the target system. Here’s a sample template for this step.
Your organization might also consider ELT — loading the data without any transformations, then using the power of the destination system (usually a cloud-based tool) to conduct the transform step.
Getting Data Out of the Warehouse
Once the data warehouse is set up, users should be able to easily query data out of the system. A little education might be required to optimize queries, focusing on:
- Tuning a complex query
- Using an execution plan
- Understanding join mechanisms
- Understand memory / disk / IO usage considerations
- Using parallelism
- Writing hierarchical queries
Data Archiving

Finally, let’s talk about optimizing your organization’s data archiving strategy. Archived data remains important to the organization and is of particular interest to data scientists looking to conduct regression using historical trends.
The data architect should plan for this demand by relocating historical data that is no longer actively used into a separate storage system with higher latency but also robust search capabilities. Moving the data to a less costly storage tier is an obvious benefit of this process. The organization can also gain from removing write access from the archived data, protecting it from modification.
Summary
This article covers tried and true practices for setting up a data warehouse. Let me know how you’re using this information in your work by dropping a comment.
